
今回はawsの可観測性・改善性構成についてみていきます。教材はこれまで同様、「ガバメントクラウド利用における推奨構成(AWS編).pdf」です。
可観測性・改善性構成
アーキテクチャは以下の通りです。パッと見たところ、可観測性はログ/アラームを示していて、改善性は自動化を示しているようです。
引用元:ガバメントクラウド利用における推奨構成(AWS編).pdf(デジタル庁)P.29
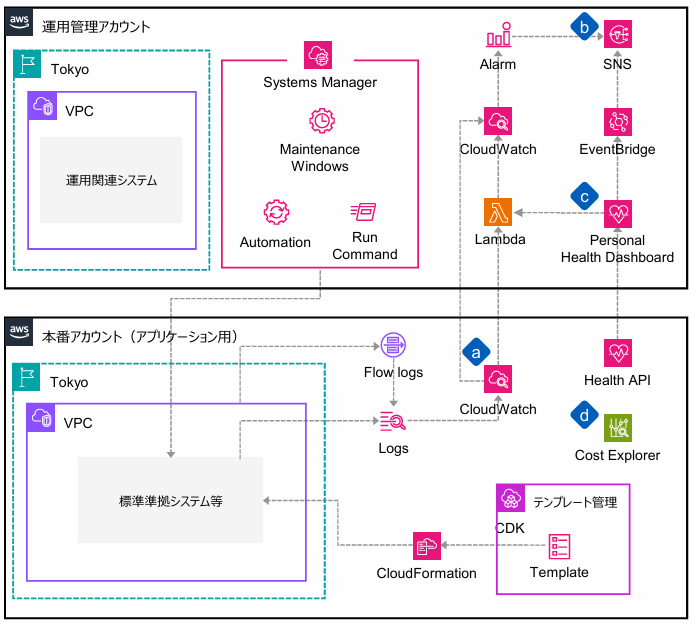
| アイコン | 名称 | 機能 |
|---|---|---|
 |
Systems-Manager | クラウド、オンプレの各サーバーのOS設定を一括管理する機能群 |
 |
Systems-Manager_Maintenance-Windows | 定期的なスケジュールタスクを実行する機能。タスクスケジューラ的なもの |
 |
Systems-Manager_Automation | awsのインフラ機能の自動実行を行う。リソース再起動等を自動実行可能で、YAMLやJSONで定義する |
 |
Systems-Manager_Run-Command | SSHコマンドを高度化したような機能で、コマンドラインの実行が可能 |
 |
CloudWatch | awsの代表的なモニタリングツール |
 |
CloudWatch_Alarm | 指定したリソース使用量が一定を超えたときに通知やアクションを実行する機能 |
 |
CloudWatch_Logs | 各awsリソースのログデータを管理 |
 |
Health-Dashboard | awsの稼働状況を表示するダッシュボード。aws自体の障害情報などを確認できる |
 |
EventBridge | イベント管理機能。イベントを受け付け、条件によってさまざまなアクションを実行する。後述のSimple Notification Serviceよりも柔軟なルール付けが可能 |
 |
Simple-Notification-Service | 簡易版のイベント管理機能。イベントを受け付け、登録したグループ(メール、SMS、HTTPS…等)に対してアクションを実行する。数千件以上の大量データの一括配信に特化。CloudWatch Alarmの裏でもこの機能が動作している |
 |
VPC_Flow-Logs | L3パケットの送信元、送信先等のメタデータを取得するログ。いわゆるFirewallログのような通信記録。Network Firewallは経路上に設定するが、Flow Logsは経路上には設定せず監視対象のリソースに設置する。あくまでメタデータのみ保持し、パケット全体は保持しない |
 |
Cost-Explorer | awsの利用料金を視覚化・分析するツール。過去13ヶ月分のデータを管理可能 |
可観測性
障害やエラー発生時に、状況を追えるようにレイヤーごとに機能を利用しているようです。確認の順番は以下のようなイメージと思います。
- CloudWatch Alarmが異常を検知
- 異常イベントをEventBridgeやSimple Notification Serviceに渡して、管理者に通知
- 管理者は、まずHealth Dashboardで定期メンテナンス、障害発生状況を確認
- ネットワークについてはFlow Logs、アプリ側についてはCloud Watch Logsを確認して異常の内容を把握する
改善性
改善性=自動化についても、レイヤーで機能を分けているようです。
- 基盤構築の自動化は、Cloud FormationやAWS CDK(Cloud Development Kit)で実行
- サーバー上のOS自動設定は、Systems Managerで実行
- その他、インシデント発生時の回復などはSystems-Manager_Automationで実行し、カバーできない範囲をLambdaにて作りこんでいく
参考資料
ページ中で利用しているAWSアイコンは、以下のページからダウンロードしたものを利用しています。
