
はじめに
これまでは業務で生成系AIを利用する場面は、一般的な要約や校正に限られていたイメージでしたが、最近では、Salesforceが発表した「Einstein Copilot」等のように、企業内に蓄積したデータを学習して、その企業・業務に特有の答えを返す「企業特化型のAI」が出て来ています。
そのような企業特化型AIであれば、不用意に機密データをAIに打ち込んで機密情報が社外流出する恐れもないため、日本での利用も増えていくじゃないかなと個人的には感じているところです。
そこで、今回はaws上で生成系AIなどの企業特化型AIが作成できる「Amazon Sage Maker」に触れていきたいと思います。
動作確認の費用
無料で使える環境「Amazon SageMaker Studio Lab」
現在、awsを利用していなくても、無料で利用可能な環境「Amazon SageMaker Studio Lab」が公開されています。
利用申請後アカウント発行まで2,3日かかりますが、無料であるため、クレジットカード情報を入力する必要もありません。その他、以下のような制限がありますが、入門編で利用する分には問題ないと思います。
- CPU利用時間は1日8時間まで。
計算結果は翌日に持ち越せるため、1回で8時間を超える学習をしなければ問題ないです - 外部公開はできない
ブラウザ上で機械学習の学習と推論を行えますが、Amazon API Gatewayにつないで外部へAPI公開みたいなことはできません
なお、本記事では利用しませんが、機械学習の動作確認だけであればAmazon SageMaker Studio Labでも十分です。(私の場合、この記事の作業の後に外部へのAPI連携も試したいため、こちらを使わないだけです)
Amazon SageMaker Studio Labを利用する場合、環境構築は不要となるため「動作確認」の章に進んでください。
本記事の動作確認にかかる費用感
awsなので、実際に動かす前に費用感を確認してみます。まずは、SageMaker自体の利用料金ですが、以下のドキュメントを確認すると2ヶ月間無料枠があるようです。
また、SageMakerの周辺機能も費用が発生するはずです。今回SageMaker Studio上で「Jupyter Lab」という機能を利用するのですが、公式リファレンス(Google翻訳結果)を見ると…
- JupyterLab ユーザーガイド
- 「JupyterLab スペースは、コンピューティングに単一の Amazon EC2 インスタンスを使用し、ストレージに単一の Amazon EBS ボリュームを使用します」
- 「デフォルトのストレージ サイズは 5 GB 」
…どうやら、EC2とEBSあたりを利用する模様。それぞれ、aws無料枠を確認します。
- AWS 無料利用枠
- Amazon EC2:750 時間無料
- Amazon Elastic Block Storage:30GB無料
加入後12ヶ月限定のようですが、軽く動かす分には費用はかからなそうです。
ただし、利用後にコンポーネントを削除するなど、このあたりのご判断は個人でお願いします。
SageMaker 環境構築
アカウント作成
まずは、awsのアカウントがあることが前提となります。アカウントの作成方法は、以下がわかりやすいため、各自で作成ください。
- awsアカウント作成方法(ハンズオン動画)
とりあえず、「04 IAMユーザーを作成する」まで実行いただければ、作業ができるようになります
SageMakerの起動
まず、awsのコンソール上部の検索バーから「Amazon SageMaker」を検索して、選択します。
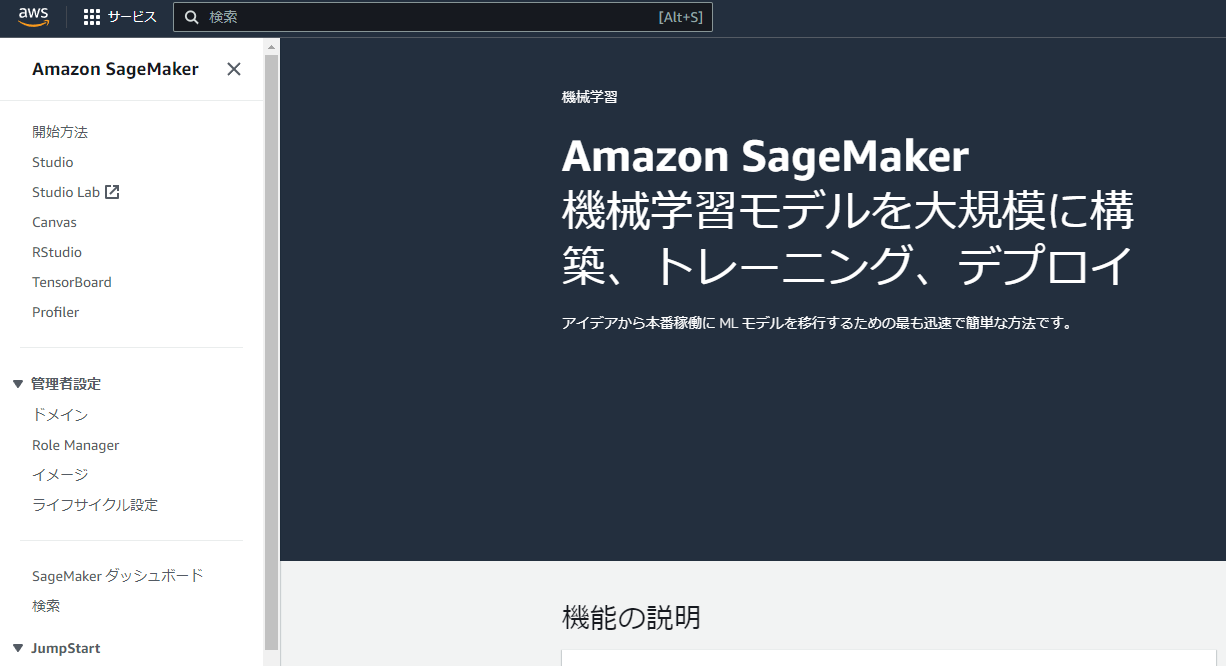
SageMakerは、利用者のスキルに合わせてAIモデルの作成方法が選択できます。
(下に行くほど、プログラマ寄り=カスタマイズ範囲が広くなります)
-
SageMaker Canvas
コーディング不要でデータ分析と機械学習モデルを構築できる。要件検討時などに、まず動かして確認する場合などに利用 -
SageMaker JumpStart
720を超える事前構築された機械学習モデルを選択して、利用することが可能。既存のモデルをカスタマイズする場合などに利用 -
SageMaker Studio
プログラム(Python)によってAIモデルを構築できる。awsに登録されていないモデルや、1からスクラッチでAIモデルを作成する場合などに利用
なお、SageMakerでは機械学習モデルを学習によってカスタマイズできますが、一般公開されている基本モデルでよい場合、Amazon Bedrockを利用したほうが楽らしいです。
今回は、SageMaker Studioを利用することにします。
ドメイン作成
SageMakerのメニューから「Studio」を選択し、遷移した画面で「SageMakerドメインを作成」ボタンを押下します。
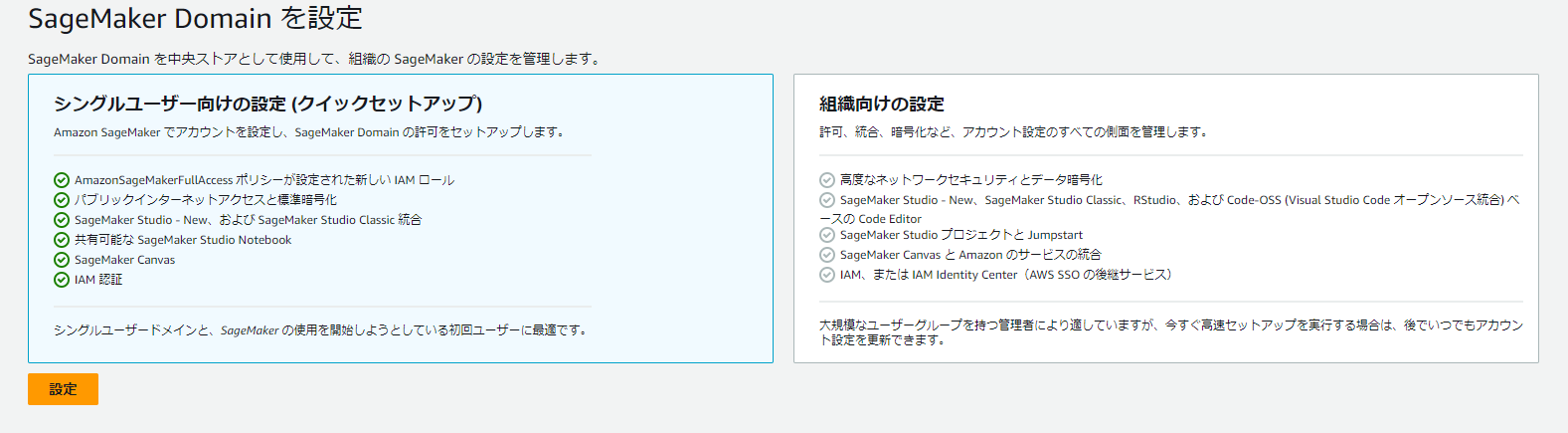
初期設定方法を選択するように聞かれるので、「シングルユーザー向けの設定」を選択します。
しばらく待つと、ドメインが完成します。作成したドメインの「起動」ボタンから、「Studio」を選択します。
スペースの作成
SageMaker Studioが起動したら、画面左上「Applications」から「JupyterLab」を選択します。

その後「Create JupyterLab space」ボタンをクリックして、スペース(インスタンス)を作成します。

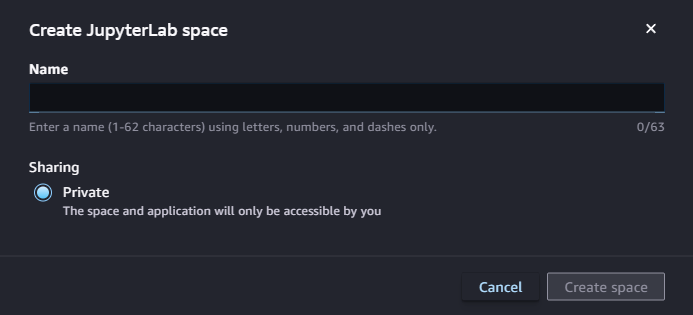
しばらく待つと、スペースができるので「Run space」ボタンで起動、「Open JupyterLab」ボタンでJupyterLabを開きます。
無事、Jupyter Note Bookが起動しました。

ちなみに、Amazon SageMaker Studio Labを利用すると、この画面からのスタートとなります。
動作確認
Jupyter Note Bookの使い方
-
画面左上の「+」ボタンを押下して、「Notebook(default:Python)」を選択すると、pythonの実行環境がファイルとして作成されます。作成したファイルを開くと以下のように、入力欄があるタブが表示されます。
-
Jupyter Note Bookでは、表示されたブロック内にpythonコードを記載して「shift + Enter」を押下することにより、コードを実行できます。試しに以下のコードを入力して「shift + Enter」を押下してみると、結果が出力されることがわかります
-
Pythonコードの実行はブロック単位になっていて、すでに実行したコードを再度「shift + Enter」で動かすこともできますし、続く処理を記載する場合は次のブロックにpythonコードを記載していきます。
サンプルコード
今回は、難しいことはせず、単回帰分析を行うプログラムを動かしてみたいと思います。
題材としては、子供の「身長」を入力に「体重」を推定する事にします。前提として、身長と体重の相関関係は一次関数であると仮定します。
最初に、各種Pythonライブラリを最新化していきます。
%conda install numpy
%conda install pandas
%conda install scikit-learn
%conda install matplotlib
%conda install pyarrow
%conda update --all次に機械学習のコードを記載します。
# 1.学習データ(0歳~10歳の平均身長、平均体重)
X = [[67.8],[80.5],[89.6],[96.9],[103.5],[110.0],[116.7],[122.5],[128.1],[133.6],[139.1]]
Y = [[8.0],[10.5],[12.7],[14.7],[16.6],[18.9],[21.8],[24.4],[27.7],[31.2],[35.1]]
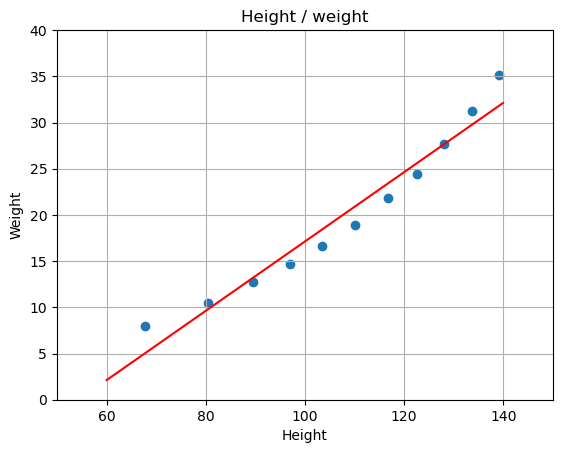
# 2.サンプルデータを表示
import matplotlib.pyplot as plt
plt.figure()
plt.title('Height / weight') #タイトル
plt.xlabel('Height') #軸ラベル
plt.ylabel('Weight') #軸ラベル
plt.scatter(X,Y) #散布図の作成
plt.axis([50, 150, 0, 40]) #表の最小値、最大値
plt.grid(True) #grid線
plt.show()
# 3.学習
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(X,Y)
# 4.学習結果をプロット
a = model.coef_[0][0]
b = model.intercept_[0]
print( '体重= ( 身長 x %g ) + %g' % ( a , b ) )
x = np.arange(60,140,0.1)
y = a * x + b
import matplotlib.pyplot as plt
plt.figure()
plt.title('Height / weight') #タイトル
plt.xlabel('Height') #軸ラベル
plt.ylabel('Weight') #軸ラベル
plt.scatter(X,Y) #散布図の作成
plt.plot(x,y,color="red")
plt.axis([50, 150, 0, 40]) #表の最小値、最大値
plt.grid(True) #grid線
plt.show()
# 5.推定値の出力
import numpy as np
weight = model.predict([[100]])
print('height = 100 cm , weight is ... %s kg'%weight[0][0] )結果と解説
-
「1.学習データ」で、以下のような学習用のサンプルデータ(Xが身長、Yが体重)を準備しています。ある人の身長がx[i]に入っていると、体重はy[i]に入っているという配列として準備します。
-
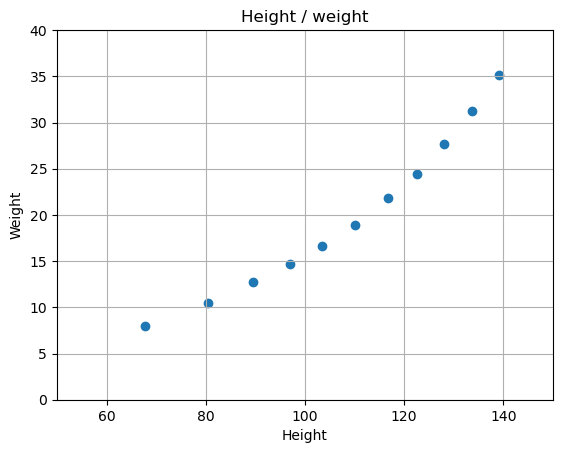
「# 3.学習」では、身長と体重の間には一次関数であらわされる関係があると仮定してモデルをインスタンス化して(18行目)、サンプルデータをもとに学習を行っています(19行目)。もし、二次関数やニューラルネットワークで学習する場合、18行目のモデルを変えればOKです。結果、身長と体重の関係は、以下の式(赤線)の回帰直線であると学習しました。
体重= ( 身長 x 0.375263 ) + -20.3931

-
最後、「5.推定値の出力」では、求めたモデル(回帰直線)に身長の値(100)を渡すことにより、体重の値を推論して出力しています。
height = 100 cm , weight is ... 17.133118807912368 kg
使い終わったら…
以上で、Amazon SageMakerの動作確認は完了です。実際に業務などで利用する場合、この結果をAPIで公開してREST連携したりするのですが、それはまたの機会にしたいと思います。
最後に、終わったらスペース(インスタンス)を忘れずに停止してから、ブラウザを閉じましょう!

